Violin Plot
Chart overview
Violin plots combine the summary statistics of box plots with the distribution shape visualization of kernel density estimation (KDE).
Key points
- Unlike Excel, which lacks native support for violin plots and requires complex workarounds, Plotivy and Python libraries allow you to create them instantly.
- They are essential for comparing distributions, detecting multimodality, and visualizing probability density across groups.
- The smooth outline is an estimate, not the data: KDE bandwidth controls everything, and the default can manufacture bumps from noise or smooth away real bimodality - if a mode matters to your conclusion, vary bw_adjust in seaborn's violinplot and check it survives.
Practical guidance
The 'cut' parameter is the other honest-plotting lever: by default the density extends beyond the observed min and max, which for strictly positive data (concentrations, durations) draws probability mass below zero; set cut=0 to clip at the data range. Violins need enough points to mean anything - below roughly 30 observations per group the shape is mostly bandwidth artifact, and a strip or swarm plot showing the actual points is more defensible in a paper. Keep the inner box or stick markers so readers get quartiles as well as shape, use split=True to compare two conditions per category without doubling the axis, and scale by 'width' rather than 'count' unless you explicitly want group size encoded - reviewers routinely misread count-scaled violins as density differences.
Create a Violin Plot with your data using AI — no coding required.
Python Tutorial
How to create a violin plot in Python
Use the full tutorial for implementation details, troubleshooting, and chart variations in matplotlib, seaborn, and plotly.
How to Make a Violin Plot in PythonExample Visualization
Create This Chart Now
Generate publication-ready violin plots with AI in seconds. No coding required – just describe your data and let AI do the work.
View example prompt
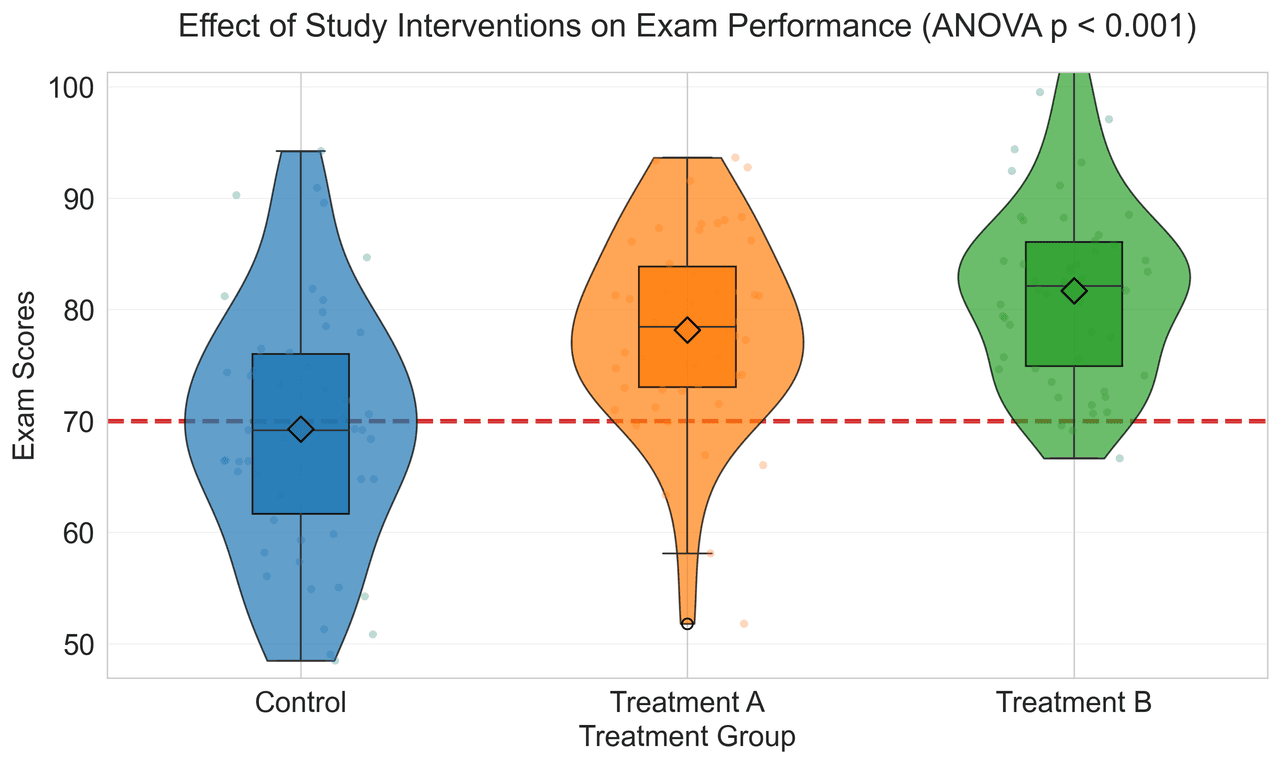
"Create a violin plot comparing 'Exam Scores' across 3 treatment groups: Control, Treatment A, and Treatment B. Generate realistic educational data with 50 students per group. Control: mean=72, sd=12 (normal). Treatment A: mean=78, sd=10 (slight improvement). Treatment B: mean=82, sd=8 (significant improvement, less variance). Include embedded box plots showing quartiles, median line, and mean diamond marker. Add individual data points as a strip plot with jitter (alpha=0.3). Perform and annotate ANOVA p-value. Use distinct colors for each group. Add horizontal reference line at passing score (70). Title: 'Effect of Study Interventions on Exam Performance'."
How to create this chart in 30 seconds
Upload Data
Drag & drop your Excel or CSV file. Plotivy securely processes it in your browser.
AI Generation
Our AI analyzes your data and generates the Violin Plot code automatically.
Customize & Export
Tweak the design with natural language, then export as high-res PNG, SVG or PDF.
Newsletter
Get one weekly tip for better violin plots
Join researchers receiving concise Python plotting techniques to improve chart clarity and reduce revision cycles.
Python Code Example
# === IMPORTS ===
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import f_oneway
# === USER-EDITABLE PARAMETERS ===
# Change: Customize data generation parameters
groups = ['Control', 'Treatment A', 'Treatment B']
group_means = [72.0, 78.0, 82.0] # Change: Means for each group
group_sds = [12.0, 10.0, 8.0] # Change: Standard deviations for each group
n_per_group = 50 # Change: Number of students per group
# Change: Visual styling
colors = ['#1f77b4', '#ff7f0e', '#2ca02c'] # Change: Hex colors for groups (must use hex codes)
passing_score = 70 # Change: Horizontal reference line position
jitter_width = 0.2 # Change: Jitter range for points
point_alpha = 0.3 # Change: Transparency for points
point_size = 20 # Change: Size of jitter points
violin_width = 0.6 # Change: Width of violins
box_width = 0.25 # Change: Width of embedded boxes
mean_marker_size = 100 # Change: Size of mean diamonds
# Change: Labels and fonts
base_title = 'Effect of Study Interventions on Exam Performance'
x_label = 'Treatment Group'
y_label = 'Exam Scores'
title_fontsize = 18
label_fontsize = 16
# Change: Plot dimensions and toggles
figsize = (10, 6)
show_points = True
np.random.seed(42) # Change: Set to None for fully random data; integer for reproducible
# === DATA GENERATION (EXPERIMENTAL DATA PRIORITY) ===
print("Generating experimental data...")
data_list = []
df_list = []
for i, (group_name, mean_val, sd_val) in enumerate(zip(groups, group_means, group_sds)):
scores = np.random.normal(mean_val, sd_val, n_per_group)
group_df = pd.DataFrame({'group': [group_name] * n_per_group, 'Exam Scores': scores})
df_list.append(group_df)
data_list.append(scores)
df = pd.concat(df_list, ignore_index=True)
# === STATISTICAL ANALYSIS ===
print("\nData Summary:")
group_stats = {}
for i, group_name in enumerate(groups):
mean_val = np.mean(data_list[i])
sd_val = np.std(data_list[i])
group_stats[group_name] = {'mean': mean_val, 'sd': sd_val}
print(f"{group_name}: n={n_per_group}, mean={mean_val:.1f}, sd={sd_val:.1f}")
# ANOVA (initialize before try)
anova_stat = None
anova_p = None
try:
anova_stat, anova_p = f_oneway(*data_list)
p_display = 'p < 0.001' if anova_p < 0.001 else f'p = {anova_p:.3f}'
print(f"\nANOVA: F={anova_stat:.2f}, {p_display}")
except Exception as e:
print(f"\nANOVA failed: {str(e)}")
p_display = 'N/A'
# Insight-driven title
title = f"{base_title} (ANOVA {p_display})"
# === CREATE PLOT ===
fig, ax = plt.subplots(figsize=figsize)
positions = np.arange(1, len(groups) + 1)
# Violin plots (primary experimental data visualization)
vp = ax.violinplot(
data_list, positions=positions, widths=violin_width,
showmeans=False, showmedians=False, showextrema=False
)
for i, body in enumerate(vp['bodies']):
body.set_facecolor(colors[i])
body.set_alpha(0.7)
body.set_edgecolor('#000000')
body.set_linewidth(1.0)
# Embedded box plots (quartiles, median; narrower to fit inside violins)
bp = ax.boxplot(
data_list, positions=positions, widths=box_width,
patch_artist=True, showmeans=False, meanline=False
)
for i, box_patch in enumerate(bp['boxes']):
box_patch.set_facecolor(colors[i])
box_patch.set_alpha(0.8)
box_patch.set_edgecolor('#000000')
# Color whiskers, caps, medians for consistency
for key in ['whiskers', 'caps', 'medians']:
for whisker in bp[key]:
whisker.set(color='#333333', linewidth=1.0)
# Mean diamonds (visually distinct)
mean_handles = []
for i, pos in enumerate(positions):
mean_val = group_stats[groups[i]]['mean']
handle = ax.scatter(
pos, mean_val, marker='D', s=mean_marker_size,
color=colors[i], edgecolor='#000000', linewidth=1.2,
zorder=10, label=f'{groups[i]} (mean)'
)
mean_handles.append(handle)
# Individual data points (strip plot with jitter, overlaid for full distribution)
if show_points:
for i, group_name in enumerate(groups):
scores_g = df[df['group'] == group_name]['Exam Scores'].values
x_jitter = np.random.uniform(
positions[i] - jitter_width, positions[i] + jitter_width, len(scores_g)
)
ax.scatter(
x_jitter, scores_g, color=colors[i], alpha=point_alpha,
s=point_size, zorder=3, ec='none'
)
# Horizontal reference line (passing score)
pass_line = ax.axhline(
passing_score, color='#d62728', linestyle='--', linewidth=2.5,
zorder=0, label=f'Passing Score ({passing_score})'
)
# Axis labels and styling
ax.set_xticks(positions)
ax.set_xticklabels(groups)
ax.set_xlabel(x_label, fontsize=label_fontsize)
ax.set_ylabel(y_label, fontsize=label_fontsize)
ax.set_title(title, fontsize=title_fontsize, pad=20)
ax.tick_params(labelsize=label_fontsize, direction='out')
# Y-limits (data-driven, with padding)
all_scores = np.hstack(data_list)
y_low, y_high = np.percentile(all_scores, [1, 99])
ax.set_ylim(y_low - 3, y_high + 3)
# Grid (subtle, y-only)
ax.grid(True, alpha=0.3, axis='y', linestyle='-', linewidth=0.5)
# Layout adjustments (prevent overlap)
plt.subplots_adjust(top=0.92, bottom=0.12, left=0.12, right=0.88)
plt.tight_layout()
# CRITICAL: Assign final plot to fig (required)
fig
# CRITICAL: Display the plot
plt.show()
# END-OF-CODEOpens the Analyze page with this code pre-loaded and ready to execute
Console Output
Group Statistics: Control: mean=72.3, sd=11.8 Treatment A: mean=78.2, sd=9.9 Treatment B: mean=82.1, sd=7.8 ANOVA: F=124.56, p=<0.0001 Interpretation: All groups differ significantly from each other (p<0.05)
Common Use Cases
- 1Comparing treatment effects across groups
- 2Salary distribution by department
- 3Test score analysis by class
- 4Bimodal distribution detection
Pro Tips
Include inner box plots for summary statistics
Use split violins for two-group comparisons
Scale violin widths consistently or by sample size
Frequently asked questions
When should you use a violin plot?
Violin plots combine the summary statistics of box plots with the distribution shape visualization of kernel density estimation (KDE). Unlike Excel, which lacks native support for violin plots and requires complex workarounds, Plotivy and Python libraries allow you to create them instantly. Common applications include comparing treatment effects across groups, salary distribution by department, and test score analysis by class.
Which Python libraries can create a violin plot?
A violin plot can be built in Python with seaborn, matplotlib, and plotly — seaborn for statistically-aware defaults on tidy data, matplotlib for precise control over axes, annotations, and journal styling, and Plotly for interactive hover, zoom, and web sharing. In Plotivy you describe the figure and it writes the seaborn code for you.
Can I make a violin plot without writing Python code?
Yes. Describe the violin plot you need in plain language and upload your dataset — Plotivy's AI writes the Python code and renders a publication-ready figure. You still get the full, editable seaborn source, so nothing is locked in a black box.
What are best practices for a clear violin plot?
Include inner box plots for summary statistics. Use split violins for two-group comparisons.
Long-tail keyword opportunities
High-intent chart variations
Library comparison for this chart
seaborn
Fastest path to statistically-aware defaults and tidy-data workflows, especially for grouped and distribution-focused violin-plot views.
matplotlib
Best when you need full control over axis formatting, annotation placement, and journal-specific styling for violin-plot.
plotly
Best for interactive hover, zoom, and web sharing when collaborators need to inspect values directly from violin-plot figures.
Scientific Chart Selection Cheat Sheet
Not sure whether to use a Violin Plot, Box Plot, or Ridge Plot? Download our single-page reference mapping the most-used scientific chart types, exactly when to use them, and the core Matplotlib/Seaborn functions.