Distribution•seaborn, matplotlib
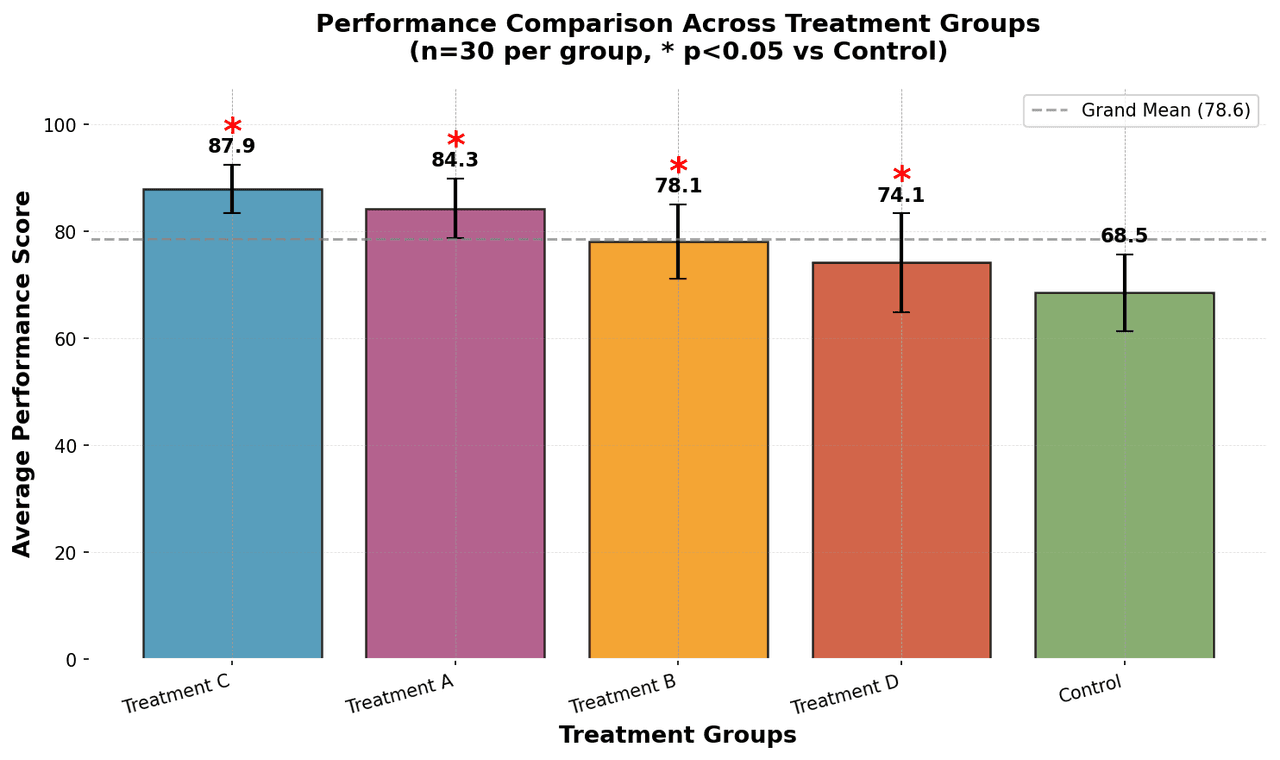
From the chart gallery•Comparing treatment effects across groups
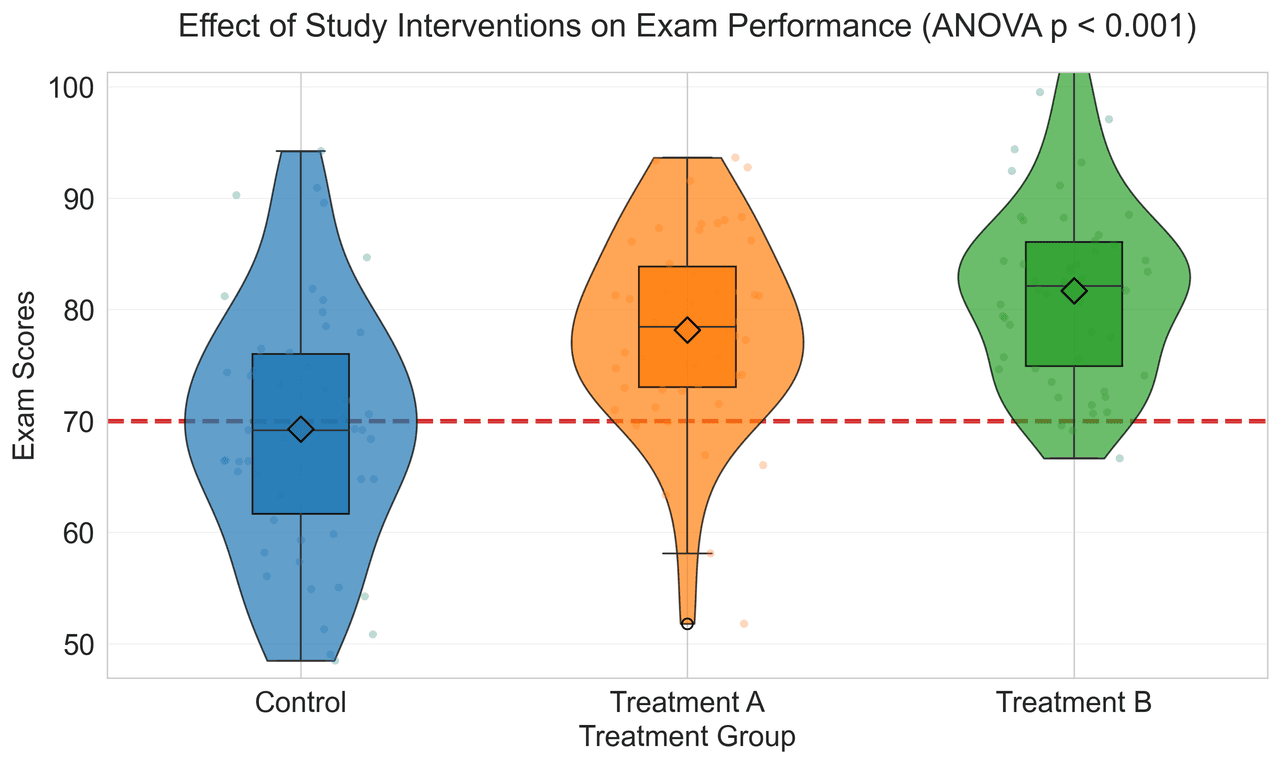
Violin Plot
Combines box plots with kernel density to show distribution shape across groups.
Sample code / prompt
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
from scipy.stats import f_oneway
# Generate exam score data for 3 groups
np.random.seed(42)
control = np.random.normal(72, 12, 50)
treatment_a = np.random.normal(78, 10, 50)